

做互联网,数据是很重要的一个东西,比如我们可以通过大量的数据来分析用户的需求、甚至获取到很多现成的赚钱项目等。
而这些,对于懂爬虫的技术人来说,可能只需要几行代码就能爬取到成千上万条数据,但是对于普通用户来说,可能需要一页一页的去翻找,这就会浪费我们很多时间。
我之前说过,我们应该把更多的时间放在更具有创造性的事情上,而这些流程化,不用脑子的事情我们可以交给机器人或者工具来帮助我们完成。
这就大大的为我们节省出更多的时间用于创造更多有价值的事情。
这也是我开这个栏目为大家分享好工具的原因,因为它能极大的帮我们提高效率。
今天要给大家分享的就是一个数据爬虫浏览器插件,它的作用就是可以帮助你爬取任何网页上的数据,比如爆款文章标题、用户评论、某博主所有文章列表等等……
它就是:Instant Data Scraper
比如,我要爬取小红书某一篇笔记下的所有评论,我只需要打开这个笔记,然后启动插件,它就可以快速的帮我爬取这条笔记下的所有评论内容:
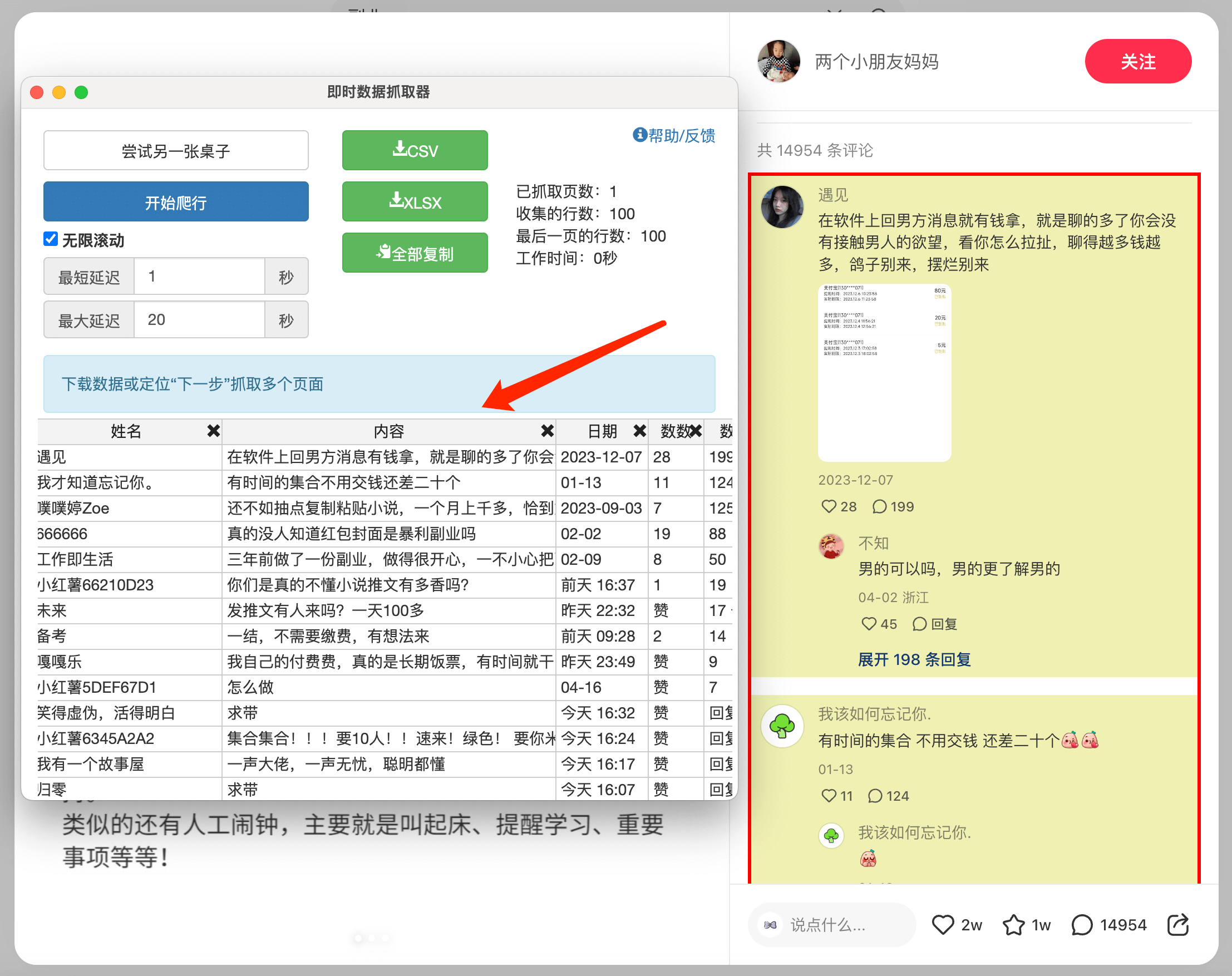
爬取成功后我们还可以直接把数据下载下来,然后对它进行分析,提取到我们想要的东西。
又或者我想要爬取小红书关于“副业”的所有爆款笔记,我只需要打开小红书搜索副业,然后在右侧选择热门内容,并启用插件,它就可以帮我快速爬取到小红书的所有和副业相关的热门笔记:
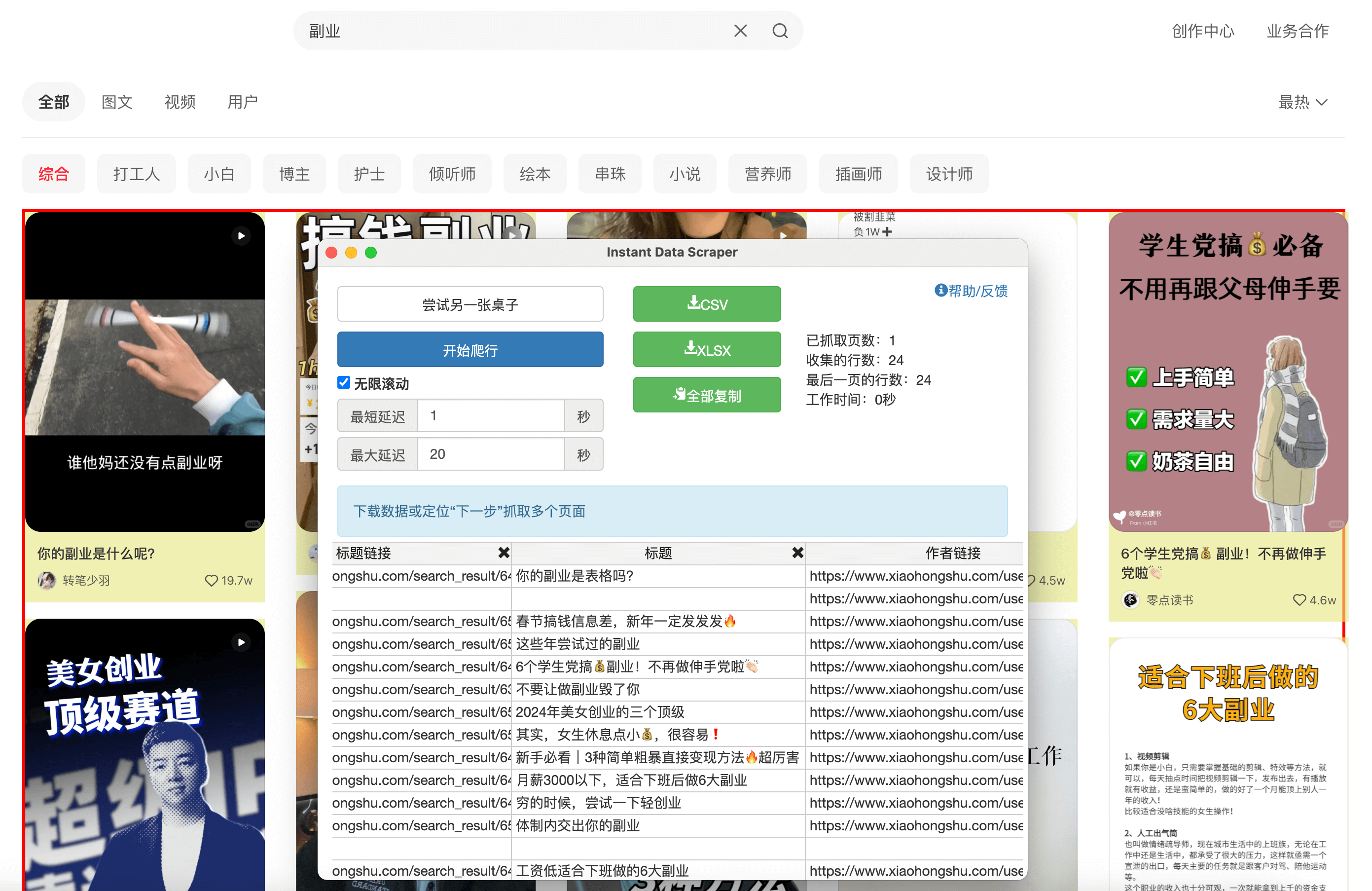
类似的做法还有很多,我就不一一举例了。
我使用频率最高的也就是上面这两个,爬取标题和评论。
它的用法非常简单,只需要把它安装到浏览器,然后打开指定页面,然后选择一个需要爬取的区域(它会自动选取,如果自动选取的位置不对,你可以点击开始爬行上方的按钮进行切换区域),然后点击开始爬行即可。
哦对了,默认是英文的,我这是因为方便大家查看,用了谷歌自动翻译。
然后如果有一些网页并不是小红书这种无限加载而是需要翻页的话,我们只需要把无限滚动关闭,然后告诉它点击哪个位置翻页,它就会自动帮我们进行翻页爬取。
可以说是非常方便的一个工具了。
小红书只是举例哟,它的用法非常多,我就不一一举例了,大家可以自行安装去慢慢玩吧。
最后,我们抓取到的数据大多都是比较杂乱的,可能很多都不是我们想要的,这个时候怎么办?有一个很简单的办法,就是找AI来帮忙,比如你把下载下来的文件直接丢给kimi,让它帮你总结并提取那些你真正需要的内容。
这样我们就几乎真正意义上的实现了完全解放双手。



感谢分享